Introduction
Reviews systems are a key feature of most online shopping sites such as Amazon. They make available to the customer the experience of multiple other customers, emulating a word of mouth opinion circulation. The force of these systems resides in the fact that the customer does not need to personally know the reviewer to get his/her opinion: it is just available on the shopping site. While this certainly helps customers which do not personally know someone who bought or tested the product they are currently interested in, it may also be misleading because the customer does not know the background of the reviewer. For instance, the reviewer previous experience in the product category, his/her grading exigencies are not always detailed in the review, thus the customer may not be able to judge the reviewer point of view, and eventual biases. Can we infer these information from the data we have on the reviewer, and provide them to the customer to help him evaluate the review ? The reviews were obtained from a dataset that contains 142.8 millions reviews spanning May 1996-July 2014.
First, let’s observe the distribution of ratings across all the Amazon’s reviews available
Clearly, we see that for every category, the grading are skewed to higher grades. The reviewers have a tendency to give high grades to the products they review. What about specific categories ? We can observe that the higher grades are given in the “Digital Music” category. This observation is easily explained as the majority of customer knows beforehand what is the music that they buy (by listening to radio, music videos …) and the quality of the goods is constant which leaves little room for disapointment. Contrary to categories like “Cell phones and accessories” or “Video games” where the ratings is directly impacted by the production quality (materials used, finitions, presence of glitches …) which increases the variance of the ratings.
If everyone gives high grades, how can we distinguish a helpful reviews from a less helpful one ? That’s where our analysis comes into action. We tried to derive a new grade for each product, by taking into account additional informations about the reviewers :
- The grading exigencies: does the reviewer tend to give the products high grades, even if they are not fully satisfactory ? Or is he very exigent and never gives a product full score, until it is really outstanding ? We tried to infer this from the set of reviews of a reviewer with a sentiment analysis of the reviews text: if the sentiment of a text is higher than the rating of a review, then the reviewer is rather exigent. On the contrary, if the rating of a review is always higher than the sentiment of the review, then the reviewer easily gives good grades.
- The reviewer expertise: what is the reviewer knowledge in the product category ? Is he qualified to assess the quality of a product ? A metric we can use to evaluate this is the number of reviews a reviewer has written in the product category: if the reviewer has written many reviews in a category, he is very likely to be able to judge the products in this category.
Before going into the depth of the analysis, let’s vizualise the number of reviews given to each product:
We can observe that the distribution nearly follows a power law. The strong majority of products (showed by the blue line) have a low number of reviews. To perform our analysis we decided to take only the reviewers and products that have at least 5 reviews: the 5-core dataset. We also chose to focus our analysis on the Electronics category as it offers a lot of product diversity and is less prone to subjectivity than other categories like Books or Video Games.
Let’s take a look at the distribution of the sentiment score for the products in the Electronic category.

The distribution looks similar to the ratings distribution, and is clearly skewed to toward 5. A vast majority of the reviews convey a very positive sentiment about their product. However, the products themselves are not so well perceived, as we can see on the graphs below:

The average distribution of the rating and sentiment score is around 4.2. This means that the products that have the most reviews are also those which get the better ratings, which skews the total distributions of the ratings toward 5.
Focus on a given product
We focus on computing a new rate for a product. We beforehand get more insight about the product itself. We display some plots to help us to visualize what’s going on.
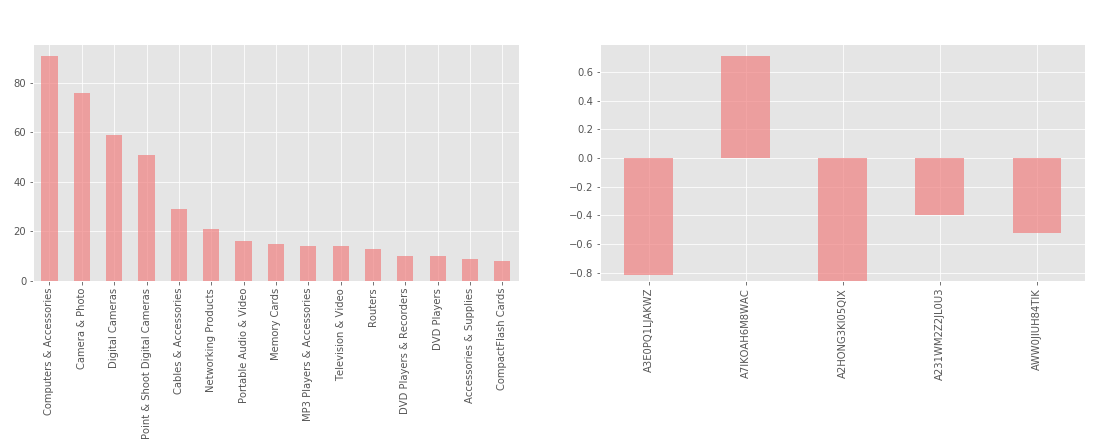
On the left graph, we can see all the categories in which all the reviewers have made a review. This whill help us later on to compute the expertise of a reviewer. The right graph shows us, for a given product, the deviation between the mean of the ratings and the current rating of the reviewers. We will use this to compute the new rates.
How to compute a new grade for a product ?
A product rating is usually computed as an average on the ratings given by the reviewers. Thus, to compute a new product rating, we first have to compute a new rating for a review ! This new rating can be divided in two parts:
- A part depending on the sentiment, let us call it
- A part depending on the rating given by the reviewer
The new rating is computed as a weighted average of the two:
where is a weight between 0 and 1 describing the importance we give to each part. If , then the new rating is the just the rating given by the user, without taking into account the sentiment analysis ; and if the new rating is entirely based on the sentiment analysis.
We want to include into the new rating as much information about the reviewer as we can. To do this, we can look at the difference between the sentiment of all his review and the average sentiment of his reviews. If this difference is positive, the reviewer liked the product more than usual, and if it is negative he did not appreciate the product as much as he usually do. The difference between a value and the average is in the interval , which we can map to to compare it to the absolute values of sentiment and ratings. Each part is thus decomposed as:
where and are the weights (between 0 and 1) given to the absolute values of Sentiment or Rating with respect to the difference to the average.
The new rating is thus computed as :
We can visualize how our new rating works on the graph below: the colors show the contribution of each part (sentiment, reviewer rating, average and absolute value) to the new rating. The reviews were taken from this product
Now that we have our new rating for a review, we can compute the new rating of a product. The new rating of the product can be computed as an average on the reviews rating, but we wish to give more weight to reviewers that are in a better position to judge a product.
How can we evaluate the experience of a reviewer with respect to a product ? Since we have access to all the reviewer reviews, we can look at the other products that the reviewer graded. If these products are similar to the one we want to rate, then we can assume that the reviewer has some experience in the product category: he has at least tested the products that he has reviewed. This is summed up in the “expertise” score of a reviewer in a category, which is computed as :
If the reviewer has graded 1 review in the same category, his expertise score is 1. If he has reviewed more, his expertise score will grow accordingly.
Finally, the new rating of a product is computed as a weigthed average of :
- the average of the new rating
- the average of the new rating, weighted by the expertise of the reviewers
is the weight given to the expertise term: if it is then only this term counts in the final grading, and if it is the product rating is computed as an unweighted average of the new ratings.
The new ratings can visualized in the plot below:
Our rating can be tuned by a customer to get a rating corresponding to his/her criteria. To improve it further, we could consider more criteria like the length of the reviews or the helpfulness rating (given by the other customer).
Citations
- Dataset : Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering, R. He, J. McAuley, WWW, 2016
- NLTK/Vader library : Hutto, C.J. & Gilbert, E.E. (2014). VADER: A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text. Eighth International Conference on Weblogs and Social Media (ICWSM-14). Ann Arbor, MI, June 2014.
- Bokeh library : Bokeh Development Team (2014). Bokeh: Python library for interactive visualization